Porting Polybench to Julia
In my previous post I gave a short introduction to my GSoC project. I described how Polly can now be used to optimize Julia code and provided a vague outlook on the kind of problems that I would have to solve. In this post I want to take up this last thought to give an overview of my recent activities.
One of the major tasks in my work is to identify situations in which Polly cannot unfold its optimization potential. That means, it's crucial to find concrete pieces of Julia code which Polly fails to optimize. However, Polly is not intended to optimize arbitrary programs - it has definite requirements on the code for which its optimizations are requested. Polly, or polyhedral optimization in general, is only amenable to certain code regions, referred to as Static Control Parts or SCoPs for short (a detailed description of such SCoPs can, for example, be found in Tobias Grosser's diploma thesis).
Fortunately, with PolyBench there exists a dedicated collection of programs that contains such SCoPs. This benchmark suite has also been used earlier to analyze Polly and its optimization abilities. However, the benchmarks that are part of PolyBench are C programs (to be exact, there also exists a Fortran version). Therefore it stood to reason to port this benchmark suite to Julia - the tentative result of this can be reviewed at my github repository.
To illustrate the performance that can currently be achieved when using Polly to
optimize SCoPs in Julia I performed a simplistic benchmark run of this PolyBench
port - the results are depicted in figure 1 below. It shows the average speedups
on 10 benchmark runs for which I extracted the execution times via Julia's
Base.time_ns() utility. It's already possible to achieve notable speedups on
some of these programs. The slowdown of others, however, may indicate problems
in the optimization process.
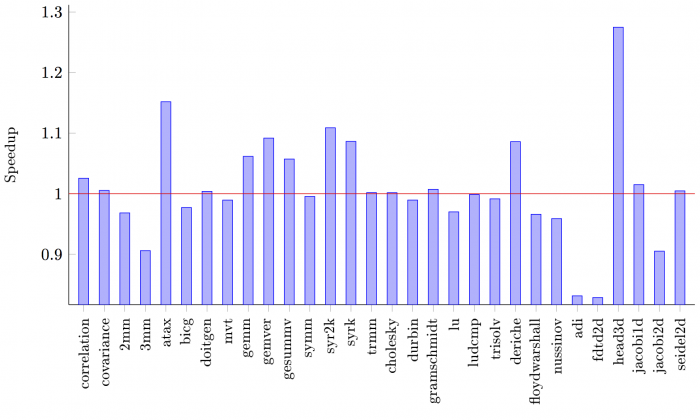
Figure 1: Speedup of ported PolyBench program with Polly enabled in Julia.
In order to get a feeling of what can be expected on these SCoPs in general, I
also conducted the original PolcBench/C benchmark suite. Figure 2 below
illustrates the comparison between the optimized benchmarks, which were compiled
via clang -O3 -mllvm -polly, and the unoptimized benchmarks, compiled via
clang -O3 (additionally, I configured PolyBench to use cycle accurate
profiling to enable exact measurements via its POLYBENCH_CYCLE_ACCURATE_TIMER
option).
On the one hand the respective results might highlight the optimization potential that could not yet be leveraged by Polly within Julia, on the other hand it might illustrate current restrictions on others. (however, some differences in the slowdowns for some of the benchmarks might possibly have emerged due to the differing approaches for the measurements)
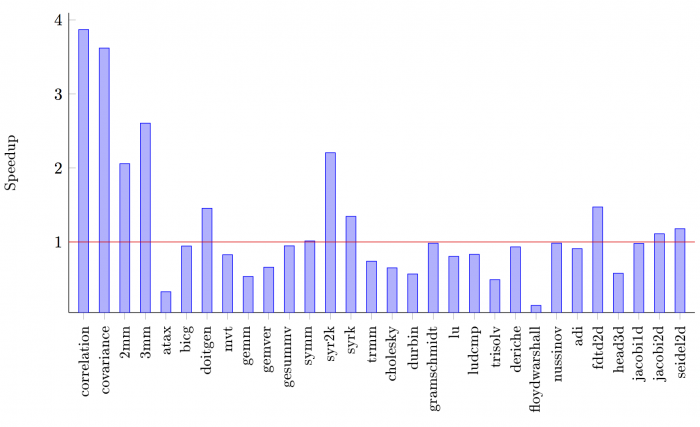
Figure 2: Speedup of original PolyBench/C programs when optimized via Polly.
What's next
This benchmark set has enabled me to systematically analyze SCoPs in Julia and continuously helps to identify characteristics of Julia's internals that currently prevent Polly from performing optimizations. In my next posts I will highlight some of these in more detail and, as last time, I’m looking forward to letting you know about prospective findings.